Thanks to the digitalization of writing and the rise of Internet searches and interactions, words have become very valuable inputs for statistical models and algorithms that allow inferring and reaching very precise conclusions about consumer behavior, among other uses.
Today, language has become the subject of big data analysis. Since the links used by Google are composed of words and the searches performed on that page are also composed of words, the study of text as data is becoming increasingly important.
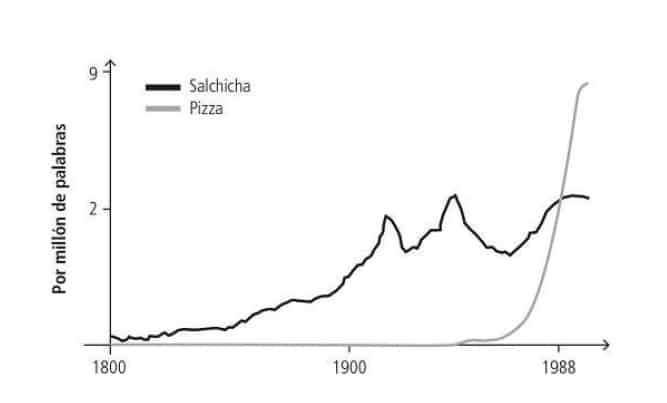
According to the book “Everybody lies: What the Internet and Big Data Can Tell Us About Ourselves,” this type of analysis can answer questions such as: what can we see in the frequency with which words or phrases appear in books in different years?
The book’s author, Seth Stephens-Davidowitz, an economist and data scientist, explains that for example, with the analysis of words or phrases appearing in books in different years, we learn about the slow rise in popularity of “sausage” and the fairly recent and rapid rise in popularity of “pizza”.
There are other fields of action to perform numerical analysis from words. The paper reviews that “… there is a powerful new tool for analyzing texts called ‘sentiment analysis’. Scientists can now estimate how joyful or desolate a particular text is.“
When in the digital environment people use words like “phenomenal”, “awesome”, “extraordinary”, “stupendous” or “wonderful”, it can be associated with people being in a moment of happiness. If these types of texts are used to refer to a product, service or brand, it is inferred that consumers are satisfied.
When you can turn words into data, you can find out what kind of ice cream people like and supermarkets could fill their shelves with it, and newspapers could establish what points of view people want and fill their pages with it, concludes the author.
